Хранилища данных
Зачем
- MS Хранилища данных
- Интегрирует множество источников данных и помогает снизить нагрузку на производственную систему
- Оптимизированные данные для доступа к чтению и последовательного сканирования диска
- Хранилище данных помогает защитить данные от обновлений исходной системы
- Позволяет пользователям выполнять управление основными данными
- Улучшение качества данных в исходных системах
Основные типы хранилищ:
- хранилища в третьей нормальной форме (3NF)
- хранилища с измерениями (типа «Звезда» или «Снежинка»)
- хранилища с измерениями Data Vault
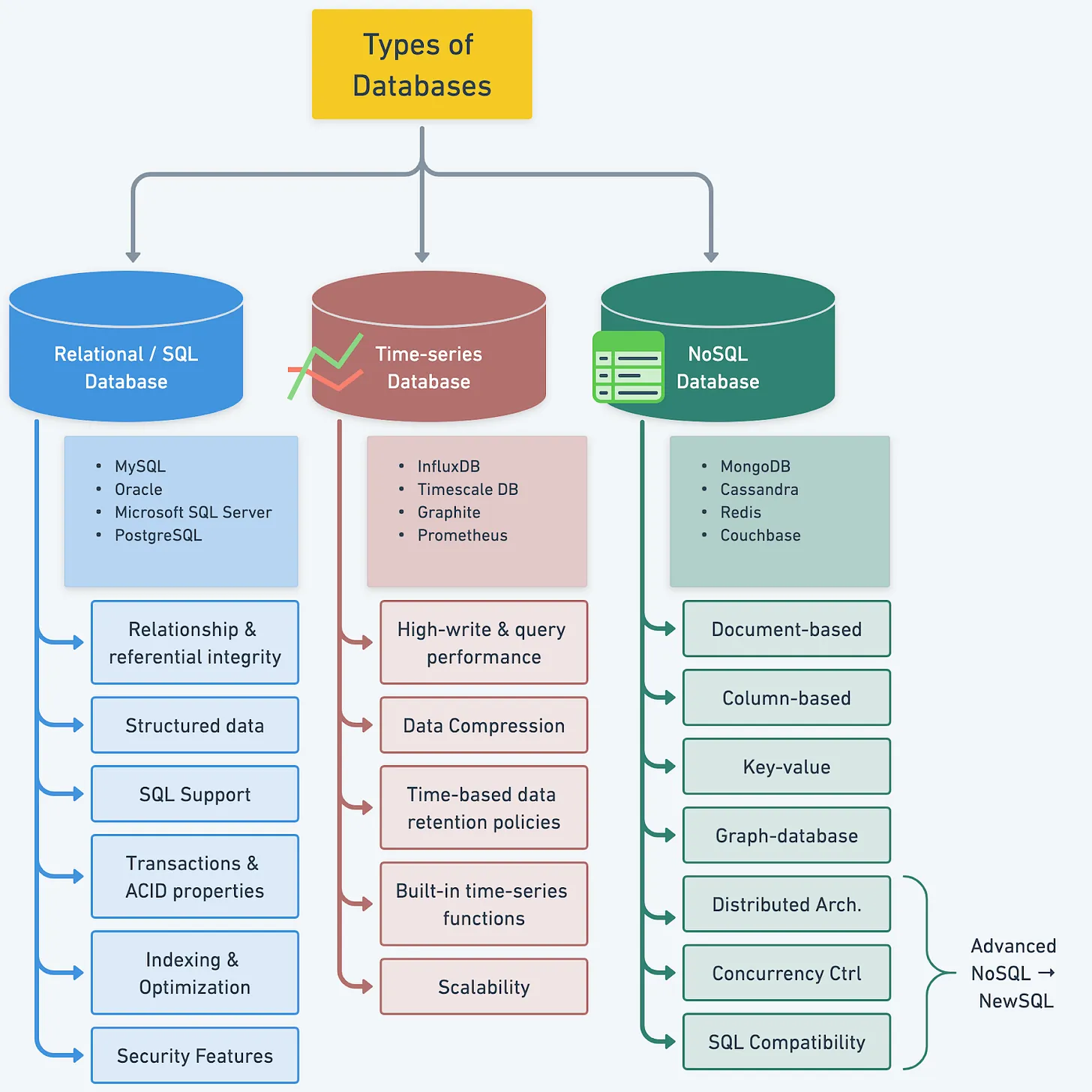
Виды
- Structured
- OLTP (MSSQL..)
- RDBMS (Relational Database Management System)
- Almost anything could be solved by them
- RDBMS (Relational Database Management System)
- OLAP
- Column Family (ClickHouse..)
- OLTP (MSSQL..)
- Time-series database (Prometheus..)
- Store and manage time-stamped data
- Semi Structured
- UnStructured
- BLOB (Minio)
Паттерны
- Модель данных звезда — оптимальная структура данных при переходе на российский BI
- Агрегированные витрины
- Materialized View
- Data Mining против хранилища данных
- On-Line Analitical Processing (OLAP) - оперативная аналитическая обработка данных
- принципы построения систем поддержки принятия решений (Decision Support System - DSS)
- хранилищ данных (Data Warehouse)
- систем интеллектуального анализа данных (Data Mining)
- Мутабельные (изменяемые mutable) или иммутабельные (не изменяемые immutable) данные
- Принципы ACID
- atomaric
- consistently
- isolation
- durability
- OLTP (Online Transaction Processing)
- CRUD обработка транзакций
- Нормальная форма отношений в РСУБД 1, 2, 3 для OLTP
- Денормализация отношений для OLAP
- В решениях 1С компромисс реализован следующим образом: События при записи в базу пишутся сразу в несколько мест
- В одном месте записи имеют мало индексов и оптимизированы под OLTP нагрузки
- в другом месте записи индексируются по всем полям и адаптированы для OLAP нагрузок
- Такие таблицы называются регистрами накоплений и регистрами сведений.
- Секционирование шардирование
Критерии выбора
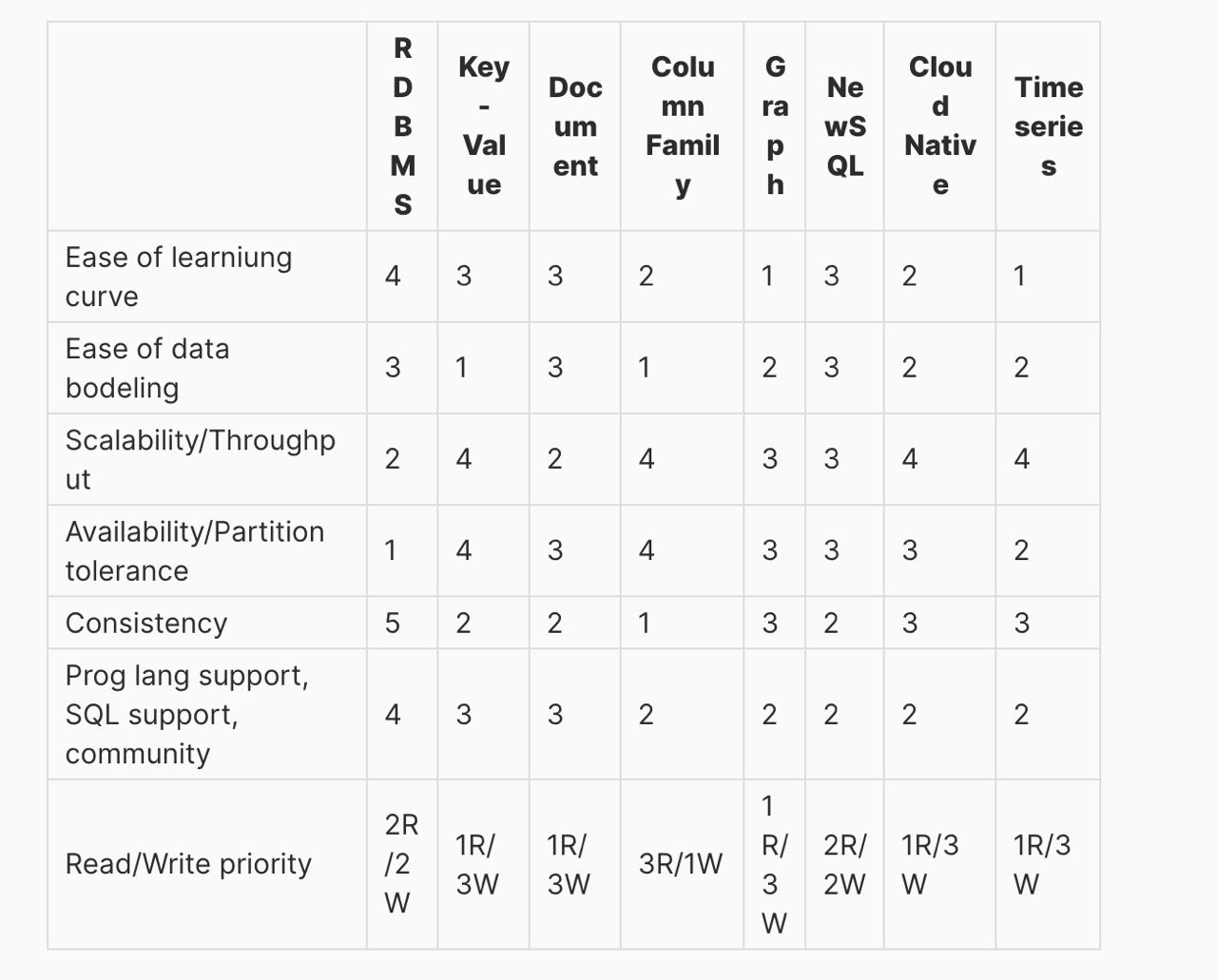
- Варианты, TOP
- SQL vs NoSQL
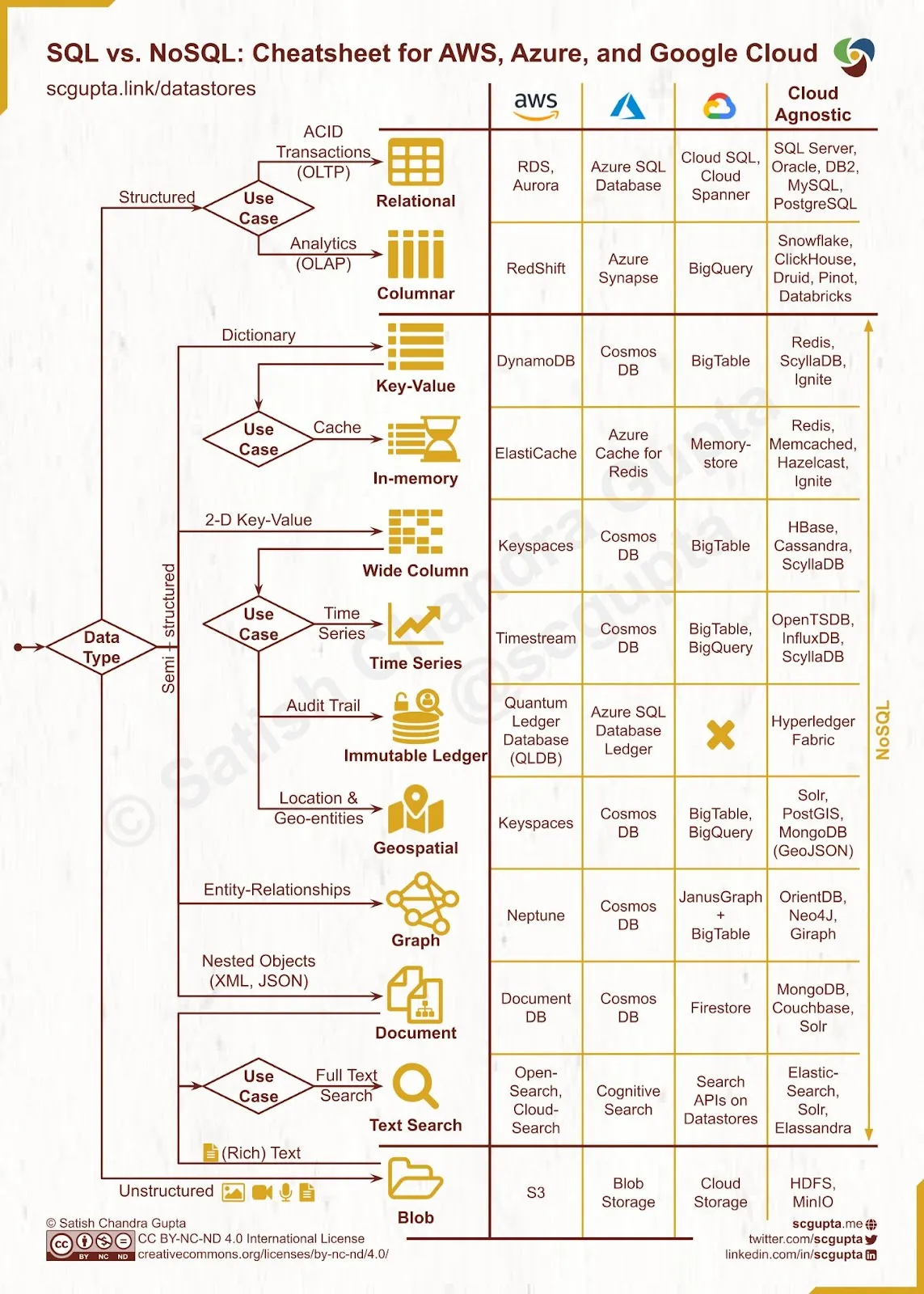
- Clickhouse vs ELK vs Google Big Query и Amazon RedShift vs TimescaleDB
- redis vs PgSQL
- Memcached vs Redis
- может показывать отличные результаты производительности в ограниченных окружениях кеширования
- А при использовании этой системы в распределённом кластере нужны дополнительные настройки. Redis же поддерживает подобные сценарии работы сразу после установки.
- SQL, NoSQL, TimeSeries
- Производительность (QPS RPS)
- более 100k RPS
- Tarantool
- до 1000 RPS
- MSSQL
- PostgreSQL
- более 100k RPS
Решение принимаем по каждому виду данных/бизнес сущности отдельно. Ищем баланс с учетом:
- размера данных
- стоимости их вычисления/чтения с HDD
- вероятности их повторной востребованности
- размера, который они занимают в кэше/частоты изменения данных/того
- насколько “болезненно” будет для пользователя получение “устаревших” данных из кэша