Debezium
Зачем
- CDC решение
- Audit logs
- MS SQL
- с версии 1.6.0, Debezium включает поддержку CDC для MS SQL Server
- Предоставляет гибкую настройку параметров маппинга загрузки данных из источника в получатель.
- определить способы трансформации, фильтрации, переименования или изменения формата данных
- Debezium использует Apache Kafka Connect framework, который предлагает различные способы преобразования данных с помощью конвертеров (converters)
- Конвертеры позволяют вам задать правила преобразования данных при передаче из одной системы в другую.
- Например, вы можете использовать
org.apache.kafka.connect.transforms.ExtractFieldдля выбора только определенных полей из сообщений - или
org.apache.kafka.connect.transforms.Castдля преобразования типов данных.
- Например, вы можете использовать
- Конвертеры позволяют вам задать правила преобразования данных при передаче из одной системы в другую.
- есть возможности использования своего собственного кода для более сложных преобразований данных. Вы можете создать собственный класс трансформации (Transformer) и указать его в настройках коннектора. Это дает вам полный контроль над процессом преобразования данных
- Логи изменения схемы БД
Плюсы и минусы
Плюсы:
- Изменения приходят полностью. Это удобно — известно, как выглядела запись до изменений и какой вид имеет сейчас.
- Работа через WAL. Чтение записей выполняется через WAL, который выступает промежуточным звеном. Благодаря этому, нагрузка на источник не увеличивается, достигается высокая скорость репликации и низкий лаг.
- Гарантированная консистентность данных. Согласованность достигается за счет использования репликационных протоколов баз данных.
- Хорошо масштабируется.
- Забор данных по механизму CDC.
- Высокая скорость работы.
- Можно использовать для репликации.
- Использует отказоустойчивую архитектуру.
- Допускает Delete на источнике в таблицах.
- Интегрирует не только SQL, но и NoSQL источники.
Минусы:
- Java
Паттерны
- писать данные в формате AVRO вместо JSON
- Миграции
- Снимки (snapshots) - может сделать снимок текущего состояния исходной базы данных, который потом можно использовать для массового импорта данных. Как только снимок будет сделан, Debezium начнет стримить изменения для синхронизации целевой системы.
- Debezium Server, готовое приложение для организации обмена данными при их миграции или модернизации существующих систем.
- Лаг репликации
Отказоустойчивость
- Debezium хранит оффсеты — отметки о прочтении записей — в файле, который легко удалить, или в Kafka, которая может быть недоступна.
- Отказ Kafka Connect
- в распределенном режиме, для этого необходимо нескольким воркерам задать одинаковый group.id
- Потеря связности с Kafka-кластером.
- Коннектор просто остановит чтение на позиции, которую не удалось отправить в Kafka, и будет периодически пытаться повторно отправить её, пока попытка не завершится успехом.
- Недоступность источника данных
- По умолчанию это 16 попыток с использованием exponential backoff
- В случае с PostgreSQL данные не пропадут, т.к. использование слотов репликации не даст удалить WAL-файлы, не прочитанные коннектором.
- Минус: если на продолжительное время будет нарушена сетевая связность между коннектором и СУБД, есть вероятность, что место на диске закончится, а это может может привести к отказу СУБД целиком.
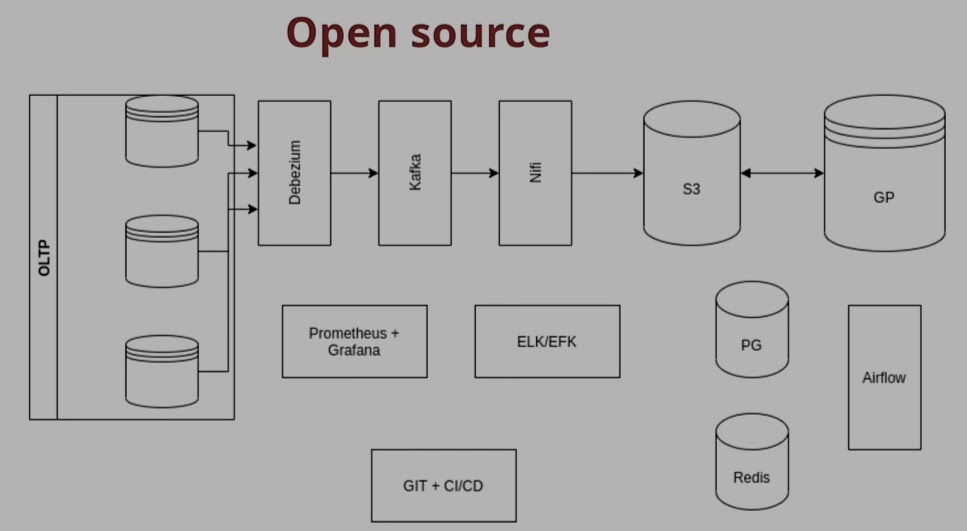
Архитектура
- Apache Kafka Connect
- Debezium Server - автономный сервер без Kafka Connect
- Debezium Embedded - встроить его в код нашего приложения в виде библиотеки- deprecated
Debezium Server
Плюсы:
- Есть готовые сборки — все дистрибутивы можно просто скачать с сайта
- Легко добавить новые source-коннекторы, в том числе работать с собственными
- Конфигурация очень простая: достаточно в конфигурационном файле указать БД-источник, БД-приёмник и параметры подключения
- Инструмент позиционируют как решение для Kubernetes, поэтому его легко масштабировать с помощью k8s
- Позволяет добавлять своё хранилище оффсетов
Минусы:
- Сложность добавления своего sink-коннектора: надо указывать зависимости и вносить изменения в конфигурационный файл.
- При каждом изменении sink-коннектора надо пересобирать дистрибутив или коннектор.
- Из коробки оффсеты хранятся в файле, в Kafka или в Redis — как и в случае с прототипом это не лучший вариант.