Индексы
Термины
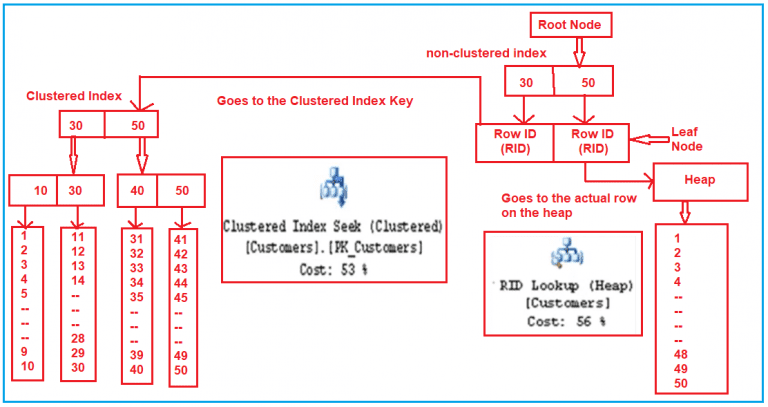
- Кластеризованный индекс
- сортирует и хранит строки данных таблицы или представления в порядке, определяемом ключом кластеризованного индекса
- реализуется в виде сбалансированного дерева, которое поддерживает быстрое получение строк по значениям ключа кластеризованного индекса.
- Некластеризованный индекс
- можно определить в таблице или представлении вместе с кластеризованным индексом или в куче
- Каждая строка некластеризованного индекса содержит некластеризованное ключевое значение и указатель на строку. Этот указатель определяет строку данных кластеризованного индекса или кучи, содержащую ключевое значение.
- Кучей
- является таблица без кластеризованного индекса. Для таблиц, сохраненных как куча, может быть создан один или несколько некластеризованных индексов. Данные хранятся в куче без указания порядка.
Паттерны
- Не все индексы одинаково полезны. При разработке индексов необходимо учитывать их селективность
- Sorts can be limited with index usage. That is, a certain sort order is supported by an index that is sorted the same way, either ascending or descending.
- Using sys.dm_db_index_physical_stats in a script to
- rebuild
- or reorganize indexes (no partitions / SQL Server 2005)
- Избыток индексов может увеличить io wait
- De-fragmentation of Index can help as more data can be obtained per page. (Assuming close to 100 fill-factor)
- Измените подходящие для Вашего сервера опции ONLINE , SORT_IN_TEMPDB,
MAXDOP=10
- Помним про 3-х повышение производительности при использовании в 2012 и в 2014 SORT_IN_TEMPDB=ON SQL Server 2014. TEMPDB Hidden Performance Gem
- Анализ плана выполнения после применения индексов: Scan, Seek, Lookup
Удаление не используемых индексов
Unused index
- Влияет на объем БД, скорость операций чтения, изменения данных
- sys.dm_db_index_usage_stats
- условия отбора по UserSeek и UserScans и UserLookups почти везде нули, что означает, что индексы не используются СУБД для работы, количество же вставок UserUpdates в них очень велико
- перезапуск службы SQL Server сбрасывает данные в sys.dm_db_index_usage_stats
Missing Index
Упрощенное средство для поиска отсутствующих некластеризованных индексов, которые могут значительно повысить производительность запросов:
- имеет ограничения и нужно тестировать предложения
- Предложения отсутствующих индексов не являются точными инструкциями по созданию индексов.
- msqsql dmv сбрасываются при перезапуске SQL Server
- параметры
- длительность выполения запроса - elapsed_time
- длительность обработки запроса CPU - cpu_time
- длительность ожидания обработки запроса - wait_time = elapsed_time - cpu_time
- user_seeks
- user_scans
- логических операций чтения - logical_reads
- логических операций записи - logical_writes
- общая стоимость запроса для пользователя - avg_total_user_cost
- эффект на пользователя - avg_user_impact
- ожидаемый эффект - estimated_improvement = avg_total_user_cost * avg_user_impact * (user_seeks + user_scans)
Предложения отсутствующих индексов в планах выполнения могут храниться для этих событий благодаря хранилищу запросов Query Store.
Проверить изменения индексов можно с помощью хранилища запросов Query Store для обнаружения запросов по отсутствующим индексам.
Рекомендации по выбору таблиц и столбцов для создания индексов
- Не индексировать
- Таблицы с небольшим количеством строк
- Столбцы, редко используемые в запросах
- Столбцы, хранящие широкий диапазон значений и имеющие малую вероятность быть выбранными в типичном запросе
- Столбцы, имеющие большой размер в байтах
- Таблицы, где данные часто изменяются, но относительно редко считываются
- Индексировать
- Таблицы с большим количеством строк
- Столбцы, часто используемые в запросах
- Столбцы, хранящие широкий диапазон значений и имеющие большую вероятность быть выбранными в типичном запросе
- Столбцы, используемые в агрегатных функциях
- Столбцы, применяемые в предложении GROUP BY
- Столбцы, применяемые в предложении ORDER BY
- Столбцы, используемые в соединениях таблиц
Рекомендации по использованию кластерных или некластерных индексов
- Использовать кластерный индекс для
- Первичных ключей, часто используемых при поиске, например номеров счетов
- Запросов, возвращающих обширные результирующие наборы
- Столбцов, используемых во многих запросах
- Столбцов с высокой селективностью
- Столбцов, применяемых в предложениях ORDER BY или GROUP BY
- Столбцов, используемых в соединениях таблиц
- Использовать некластерный индекс для
- Первичных ключей, хранящих последовательные значения идентификаторов, например идентификационных столбцов
- Запросов, возвращающих небольшие результирующие наборы
- Столбцов, используемых в агрегатных функциях
- Внешних ключей