Kafka
Зачем
Реализация паттерна интеграции Message Broker.
UC:
- большие данные BigData и потоковую обработку Streaming Data
- Log processing and analysis
- Data streaming in recommendations
- System monitoring and alerting
- CDC (Change data capture)
- System migration
Плюсы и минусы
Плюсы:
- распределенный горизонтально масштабируемый
- отказоустойчивый журнал коммитов
- кластер серверов
- Шардинг из коробки
- Поток событий
- согласованность данных
- репликация топиков (replication-factor)
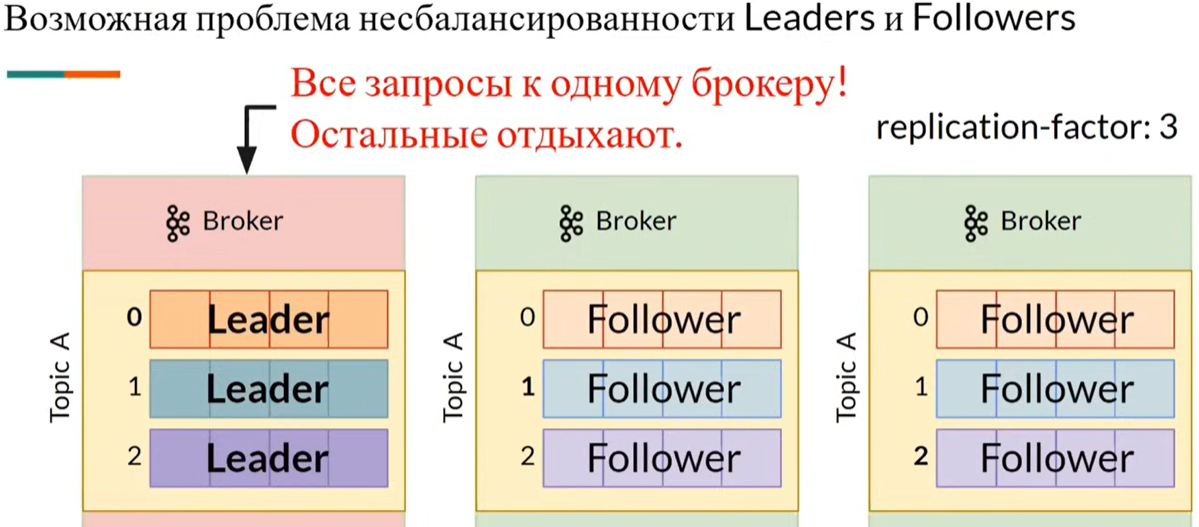
- master-slave (Leader-Follower)
- возможна задержка в данных. Запись сообщений всегда в Leader. Follower получает pull от Leader сообщения периодически
- in-sync replicas (ISR) - синхронная запись в Follower partition, замедляют запись сообщений
- репликация топиков (replication-factor)
- Strict message ordering (FIFO) by partition
- Message retention for extended periods, including the possibility of replaying past messages
- Сообщения в Kafka не удаляются брокерами по мере их обработки консьюмерами — данные в Kafka могут храниться днями, неделями, годами
- Благодаря этому одно и то же сообщение может быть обработано сколько угодно раз разными консьюмерами и в разных контекстах
- Группировка сообщений в пачки
- транзакции между несколькими топиками
Минусы:
- Наиболее полно API Kafka поддерживается только в языках Java и Scala. В других языках поддержка не всегда полная, поэтому фреймворки Kafka Connect и Kafka Streams созданы.
- Нет приоритета сообщений
- к минусам модели Pull можно отнести потенциальную разбалансированность нагрузки между разными консьюмерами и более высокую задержку обработки данных
- разбалансировка партиций по брокерам кластера, может требоваться ручная балансировка по брокерам больших партиций
Функции
Фундаментальное отличие Kafka от брокеров очередей состоит в том:
- как сообщения хранятся на брокере, но есть ttl
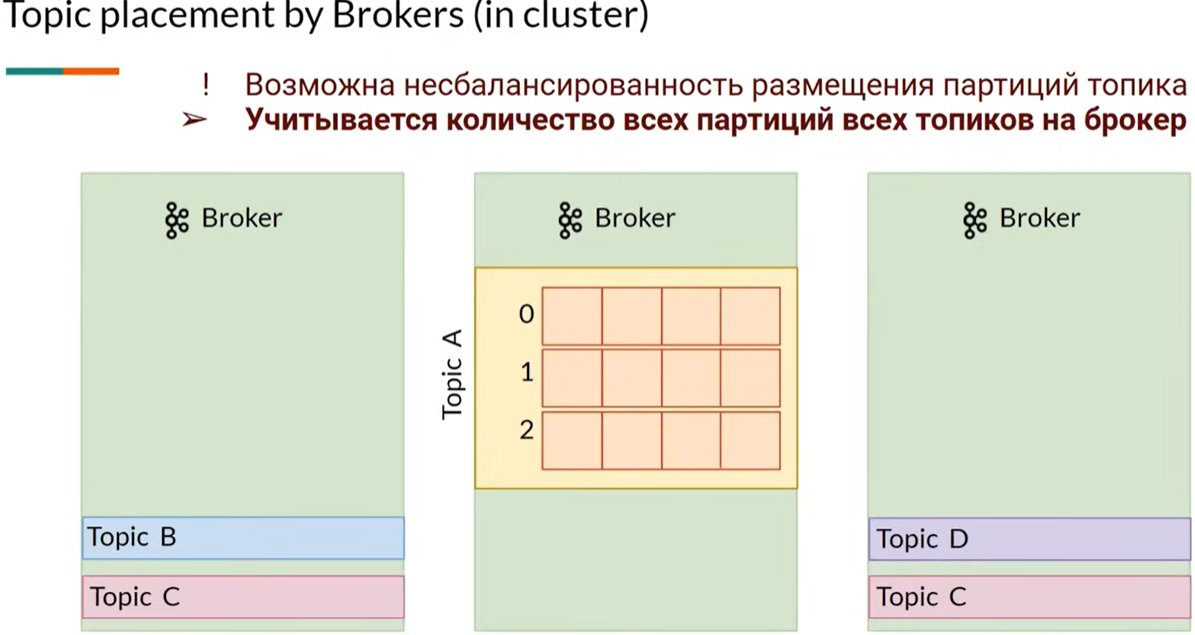
- Сообщения в Kafka организованы и хранятся в именованных топиках (Topics), каждый топик состоит из одной и более партиций (Partition), распределённых между брокерами внутри одного кластера.
- как потребляются консьюмерами (consumer)
- используется подход pull (в RMQ push по умолчанию): консьюмеры сами отправляют запросы в брокер раз в n миллисекунд для получения новой порции сообщений
- позволяет группировать сообщения в пакеты (batch), достигая лучшей пропускной способности
- Консьюмеры
- отмечают (commit) обработанные сообщения с помощью оффсетов. Оффсет (Offset) – это номер сообщения в партиции
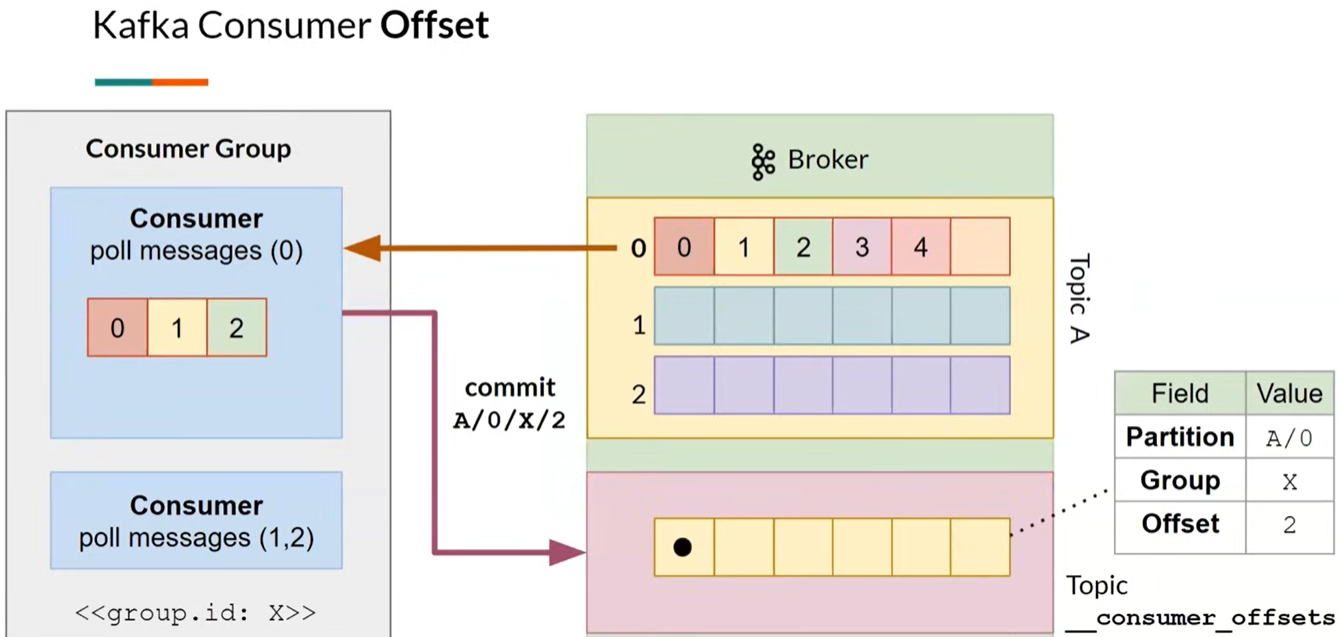
- либо об успешной обработке (offset-commit)
- либо об ошибке (offset-reset)
- type of commit
- auto commit - сразу после получения сообщения, до обработки: at most once (риск miss message)
- manual commit - после обработки сообщений: at least once (риск duplicate message)
- custom offset managment: exactly once
- consumer group - параллельное чтение данных из partition
- отмечают (commit) обработанные сообщения с помощью оффсетов. Оффсет (Offset) – это номер сообщения в партиции
- используется подход pull (в RMQ push по умолчанию): консьюмеры сами отправляют запросы в брокер раз в n миллисекунд для получения новой порции сообщений
- produce публикация сообщений
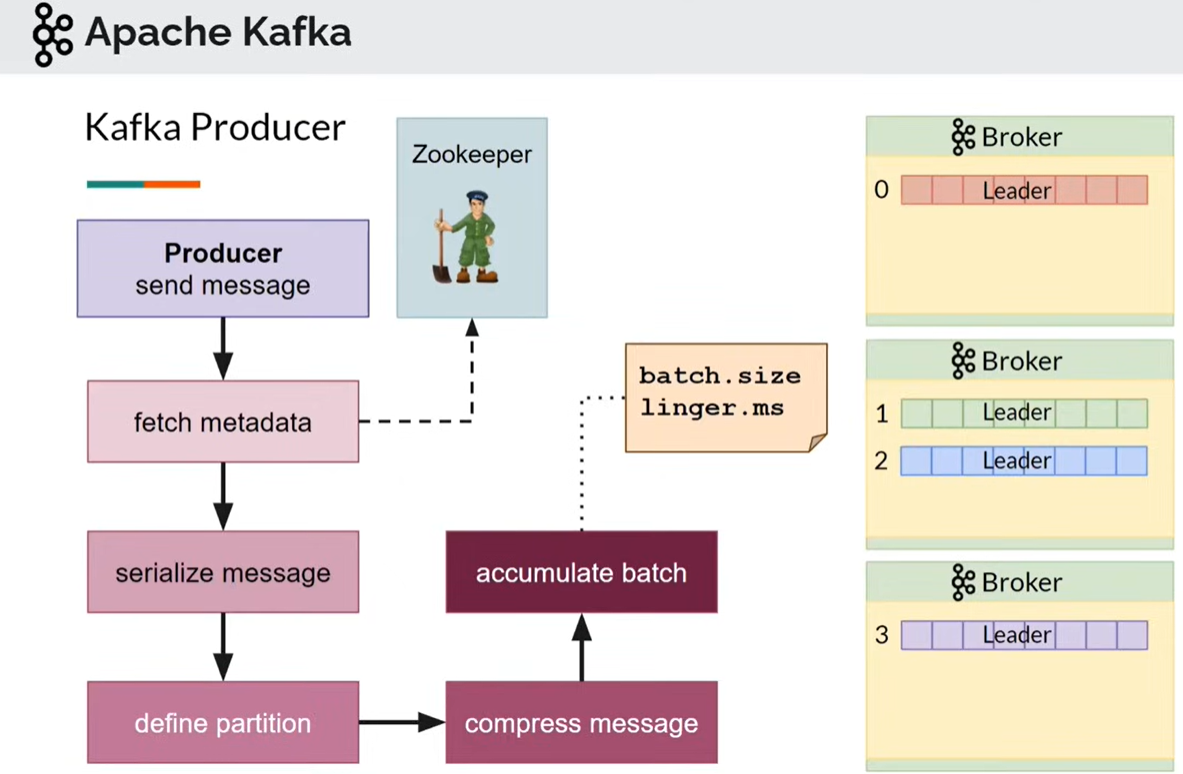
- acks - гарантия доставки, ожидание подтвеждения
- 0 нет
- 1 only Leader
- -1 all ISR
- delivery semantic
- at most once (не более одного)
- al least once (хотя бы один)
- exactly once (idempotent)
- serialize
- define partition:
- explicit partition
- round robix
- key
- compress
- accumulate batch
- acks - гарантия доставки, ожидание подтвеждения
Паттерны
- Один producer создается для отправки сообщений для быстродействия (fetch metadata sync тяжелая операция)
Модель
Каждое сообщение (event или message) в Kafka состоит из:
- ключа
- значения
- таймстампа
- и опционального набора метаданных (так называемых хедеров)